A major part of PARADISEC’s effort goes in finding and digitising audio tapes that record performance in the many small languages of the world. As discussed in a number of posts on this blog it is becoming urgent that these tapes are digitised while they are still playable. Of the tapes described in this earlier post about tapes from Madang in PNG, some are already so badly damaged by mould that they can’t be played anymore.
In order to find more tapes we run a survey http://www.delaman.org/project-lost-found/, that, unfortunately, has only ever had sixteen responses. We have managed to negotiate with these respondents to digitise five of their collections so far (see also the earlier blogpost ‘Where are the records?‘).
A more focussed way of finding out what recordings there are is by comparing what is published about a language with what primary records are listed as being in an archive. Assuming that someone doing fieldwork and writing a grammar of a language in the past fifty years must have made some recordings then the mission (should we choose to accept it) is to find those recordings.
The Open Language Archives Community (OLAC) harvests the catalogs of 60 archives of primary data every day and lists what is in them for each language of the world. These repositories include the DoBeS and ELAR archives (both associated with funding programs over the past decade), see a list of all OLAC archives here: http://www.language-archives.org/archives.php.
Putting this information into a documentation index (see the earlier discussion here) then provides an overview of where languages need more work, or, if we could identify places where linguists have already worked but nothing is in an archive, which linguists need to be helped to archive their records.
In order to follow this up, there needs to be a way of quantifying what OLAC lists per language. We developed a tool, the OLAC visualiser, that takes the OLAC information and simply counts how many items there are per language, and does that once a day. This is then mapped and presented here: http://115.146.88.224/#/. The sourcecode for the OLAC visualiser can be found in github.
Having developed this set of data it was then possible to compare it with Glottolog’s listing of grammars, looking for any grammars produced in the recent past for a language which has few items in OLAC. For example, the language Lewo has work published in the recent past as can be seen here: (http://glottolog.org/resource/languoid/id/lewo1242) but the OLAC listing for Lewo shows that just 26 items, mostly early historical manuscripts, are available in an archive (http://www.language-archives.org/language/lww). This suggests that approaching the linguist who worked there most recently may locate audio recordings that could be digitised.
Of course it is possible that the primary records are archived somewhere that does not get picked up by OLAC, in which case we can enter a record into an OLAC catalog that points to the item and thus maximise its discoverability (as discussed in Thieberger 2016 and in the blogpost here).
Robert Forkel at Glottolog kindly combined our OLAC data for languages with fewer than 40 resources with the Glottolog list of languages with a grammar written in the past 50 years (http://glottolog.org) and we came up with the following results.
There are 1708 items listed as being grammars produced since 1967, of which 1253 are of languages that have fewer than 40 items in an OLAC archive.
300 of these languages have between 20 and 39 items in OLAC
953 of these languages have between 1 and 19 items in OLAC
683 grammars are listed as appearing since the beginning of 2000 in Glottolog, but of those languages, 292 have fewer than 10 items in an OLAC repository, 439 have 19 or fewer items in an OLAC repository, and 555 have 40 or fewer items in an OLAC repository. So, even in the era of Language Documentation (that is the period following publication of Himmelmann’s 1998 paper), there are too few language recordings being archived.
As discussed in several earlier posts, there is a long way yet to go to ensure that linguists archive their current field records. And there is still a significant effort required to locate recordings made in the past by now retired or deceased researchers.
* Thanks to Marco La Rosa for work on the OLAC data visualiser and to Robert Forkel for linking our data to Glottolog’s list.
References
Himmelmann, Nikolaus P. 1998. Documentary and Descriptive Linguistics. Linguistics, 36, 161– 195.
Thieberger, Nick. 2016. What Remains to be Done–Exposing Invisible Collections in the other 7,000 Languages and Why it is a DH Enterprise. Digital Scholarship in the Humanities. http://dx.doi.org/10.1093/llc/fqw006 (Available here: http://nthieberger.net/DSHWhatRemainsToBeDone.pdf)
 Follow
Follow
I certainly feel that it is very important to have all of the language materials that I have collected archived and accessible by both members of the language communities and scholars – with the proviso that any recordings identified as needing to have access restricted can be so restricted.
However the desire to do this and the practicality of doing it are two very different things. I am fully aware that there is a huge proportion of the linguistic data that I have collected not properly archived at each of the three archives that I work with – PARADISEC, ELAR and DoBeS. Partly this is because of the quantity and diversity of the materials, tens of thousands of individual recordings; and partly it is because of the complex metadata requirements, particularly for the DoBeS and more recently ELAR archive, which base metadata on the IMDI system. While ARBIL and more recently CMDI have somewhat reduced the burden on us, the task is still so large that it may take years to actually complete archiving all of the materials I have already collected. I do keep very comprehensive metadata in the field, in terms of Word Documents in table format. (This is somewhat easier that doing the same thing in Excel because in Excel it is harder to make longer entries into the .xls spread sheets). However transferring all of this into ARBIL is very time consuming and the requirements of a teaching and research position just don’t allow time for this.
Stephen, this points (again) to the need for a simpler way of capturing metadata (see the earlier post on this here: http://www.paradisec.org.au/blog/2016/06/results-of-the-metadata-survey/) and to create a tool that does more of the work of linking descriptions to files than our present tools do. There is a working group thinking about this, coming out of the Tools and Methods Summit in Melbourne a few months ago.
Simon Greenhill has prepared a summary of the same OLAC data:
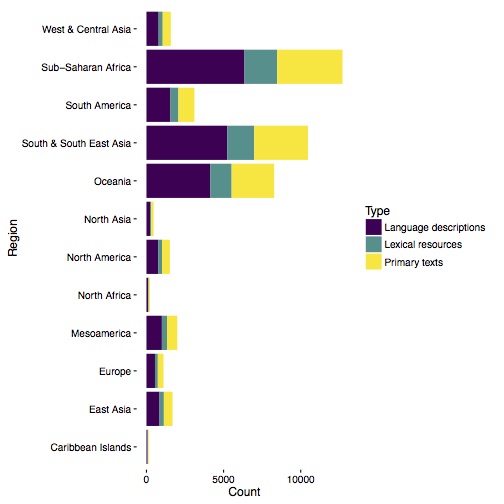
This shows relative numbers of language descriptions, other language resources, and primary text in the Open Language Archives Community’s aggregation of information from its subscribing archives, by region.